
Foreword
This document tries to explain how data is to be stored when using gaedo-blueprints. Obviously, concepts regarding gaedo are supposed to be understood here (namely the distinction between managed classes - the beans that are persisted - and service classes -the objects that are used to persist those beans).
As an aside, a basic knowledge of what graphs are (and arent) could be useful.
Finally, knowing how blueprints and its specific neo4j adaptation layer work is of obvious use (as theyre used in all examples and unit tests for gaedo-blueprints).
How to store an object graph into a persistent graph ?
A simple question, no ? Well, in fact, not so.
Lets start with a basic example our beloved Tag class (see in gaedo-test-beans) in its first version.
If we look at that class its fields are few :
public class Tag extends Identified implements Serializable {
private static final Logger logger = Logger.getLogger(Tag.class.getName());
private String text;
}
Storing properties as properties
We could imagine storing each of the non-static (and non-transient, of course) fields of that class as one of Tag associated vertex properties. Something like text could do the trick, no ? This simple solution would lead to that graph :

Well, it would immediatly raise some issues :
- What if two Tag share the same text ?
- What if Tag class had a subclass containing an other text property.
Storing properties as edges
Both issues can be solved by changes in the storage paradigm to make it converge with some basic concepts of graph theory.
- Each property of an object should be stored as an edge linking the object (as edge source) to the property value.
- Each edge name should be built from class name and property name instead of simple property value
Which lead to this second simple graph :

Well, this second graph is better by multiple aspects. Indeed, as relationships are named from class (implementation uses full class name, instead of this tutorial-level one which uses simple class name) and property name, there is now only one relationship linking a Tag to its text, and its named Tag:text. which is a good name. Furthermore, any Tag using the "tag text" text will be linked to this very vertex. Which is undoubtly a very ood thing if we plan to find all Taginstances using this text (dont worry, queries will have their very own documentation).
But
What if I want to use the "3" text ? Will instances be linked to the vertex that also represent the 3 integer number and the 3.0 float number ? That question troubled me a lot.
And what if I want to use the "Tag:1" text ? That object is clearly not the same that Tag:1 is, no ? But, according to previous definition, they would be stored using the same vertex, which is now visibly unthinkable.
Adding type informations
So I introduce here some supplementary properties (which will make that graph even more semantic-a-like)

These properties are kinda special, let me explain them a little more
- kind can be uri, for vertices linked to others, bnode for vertices without specifc ids, and literal for all those literal values you know and love (like strings, numbers, dates, and so on). That kind property is defined on all vertices gaedo access.
- type is defined only on vertices of literal kind. It contains a definition of the type used for that value. Notice that, instead of using standard Java type, I try to use semantic visions of those types. As a consequence, a Java string will be represented by a xsd:string.
Were quite at the end of that introduction to gaedo graph storage. Except for one thing a Tag is a Tag, but its also an instance of all its superclasses (like Identified, as an example). Suppose, as an example, were looking for all Identified instances which id is greater than 3. How could we do ? We could explore the java classes extending Identified (as an example using reflections) then search all of their instances. But, admit it, its clearly not oriented towards graph navigation : this kind of process would be like taking some nodes quite at random to examine them.
Adding links to classes
This leads to the effective implementation exposed below
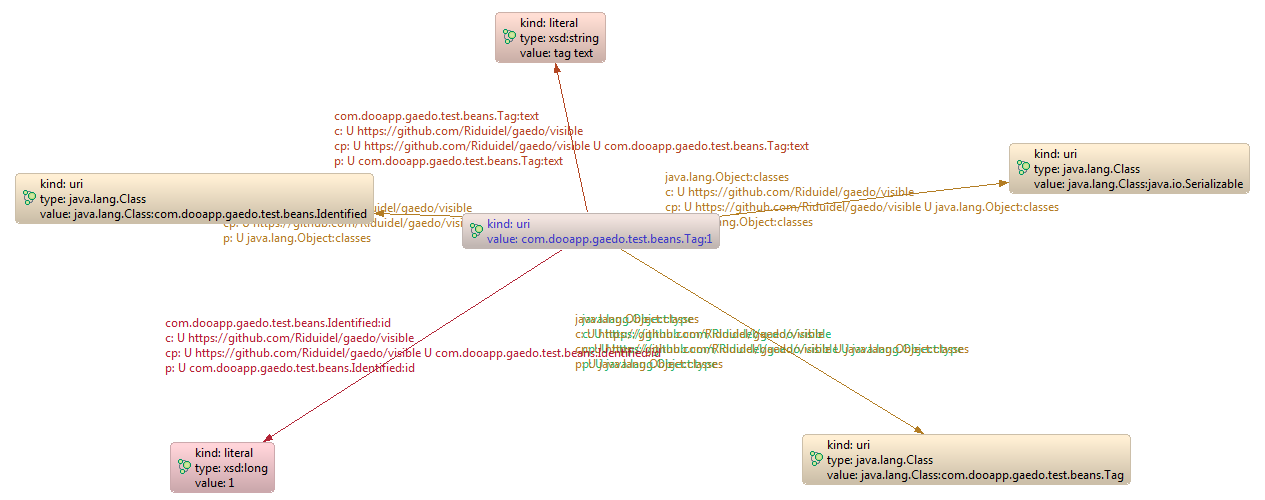
You can see that each object is linked to all of its classes using the Object:classes edge. Furthermore, it is linked to its effective class using the Object:type edge. One should notice that these edge exist, even if the object expose absolutely no property regarding its classes (which is the case of the Tag class).
So, to your mind, is it possible to recreate the Tag object this graph represents ?
We know some things :
- its com.dooapp.gaedo.test.beans.Tag:text is a string which value is "tag text"
- its com.dooapp.gaedo.test.beans.Identified:id is a long which value is 1
- its java.lang.Object:classes are Identified, Serializable and Tag
- and its java.lang.Object:type is also Tag
which makes it a Tag with id 1 and text tag text.
One may however ask where is the Tag#rendering property. It is easy, it is missing. And it is missing because its value is null, which we never represent.
Conclusion
As one can see, the implementation rendered is conceptually similar to the one a SaigGraph can produce, and for a good reason : all objects stored by gaedo in graphc an be exported as RDF statements, like GraphPostFinderServiceTest#allowExport() test method clearly shows.
But, as the documentation about queries explain, it is absolutely not the only advantage of that persistence strategy.